ChatGPT Wrapped
A local-only web app that turns a ChatGPT export into a stats dashboard. I built it to practice turning the kind of analysis I did at UCI Health into an engineered product, and to learn frontend work by connecting a UI to my own backend.
· 3 min read
Moving On From Notebooks #
I spent 4.5 years doing analytics at UCI Health, and most of my work lived in Jupyter notebooks and CSV files. That work supported real clinical research, which has strict requirements for keeping data and our analyses auditable and secure. This is, of course, far different than shipping software that users run. I really wanted to move in that direction so I spent a year on CS fundamentals through Stanford (data structures and algorithms, discrete math, linear algebra), then went looking for a project that would force me to turn an analysis into an actual product. Inspired by the shiny Spotify Wrapped screenshots on my Instagram stories, I decided to do the same for my ChatGPT history.
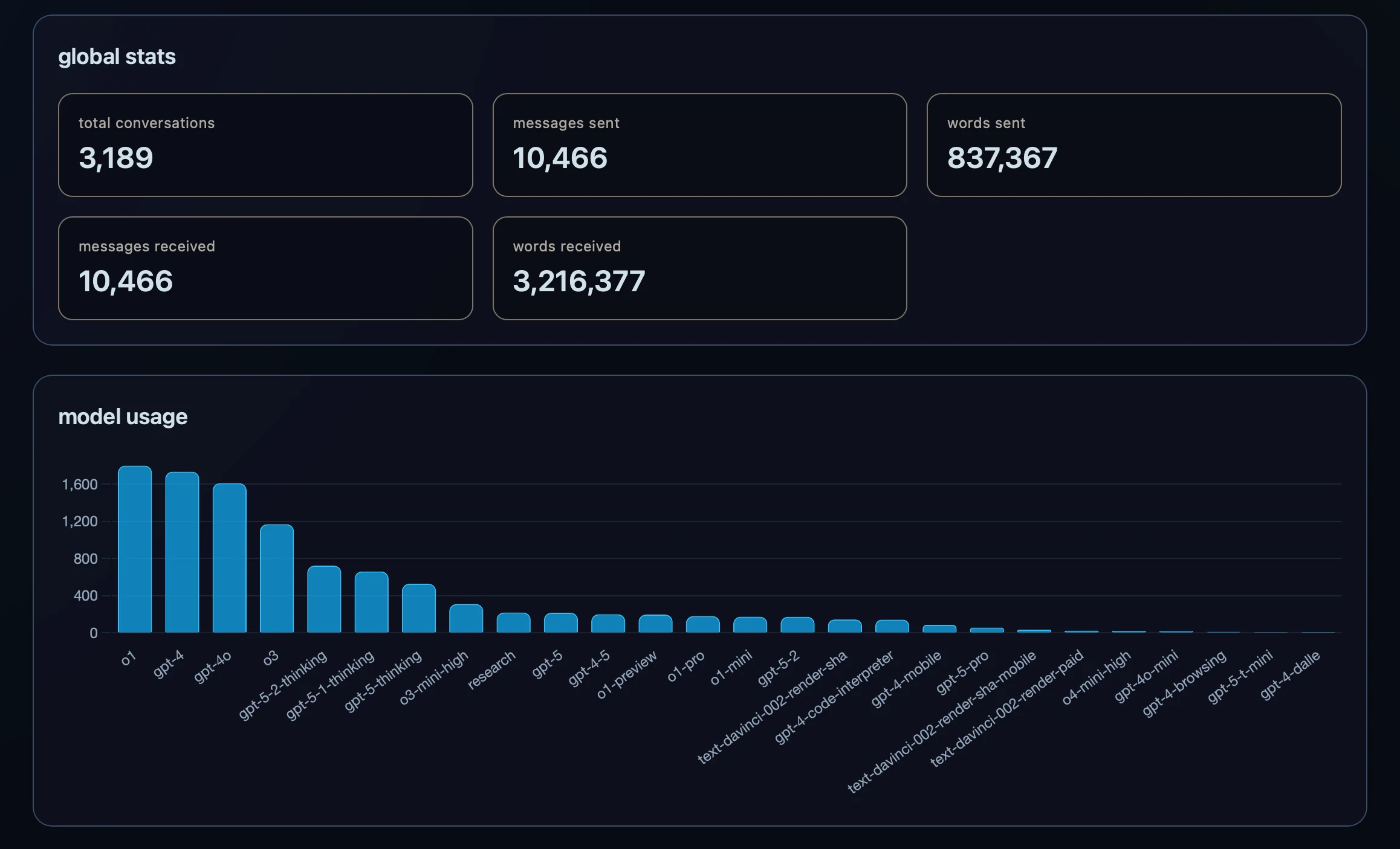
THE PROBLEM: A ChatGPT export is one big conversations.json file (mine was 167 MB) where each conversation is stored as a directed acyclic graph (DAG) of message nodes rather than a flat list. The new part for me was switching to an engineering-focused perspective: input validation, error handling, tests, an API, and a frontend. The part I was very familiar with was keeping data secure. I knew I didn’t want any conversation data to leave my machine.
MY APPROACH: A FastAPI backend exposes a single data endpoint. You upload the export, the parser flattens each conversation graph into messages, a stats module computes aggregates in memory, and the response goes straight back to the browser. There is no database, no disk write, and Docker Compose binds both containers to localhost, so nothing is reachable from outside the machine. Only aggregates reach the frontend (message counts, model usage, time-of-day buckets). The frontend is Svelte with Chart.js for the charts, plus Tailwind to make it easier to keep some unity in the design.

THE LEARNING PROCESS: The backend felt like home, since flattening a messy nested structure and bucketing timestamps is ordinary analytics work. Connecting it to a frontend was the new experience. I had never built a UI against my own API, and I gave myself a crash course in Svelte. I used Codex with GPT-5.3-Codex during the build, which was helpful for boilerplate and wiring everything up. The other lesson was workflow. My first attempt was messy commits and two abandoned prototypes. Then I switched to Codex and rebuilt the project the way I would want to work on a team: 10 small pull requests, each tied to a GitHub issue, with the checks I ran written into the descriptions. I heavily expanded on this process in Custom Agents from Scratch.
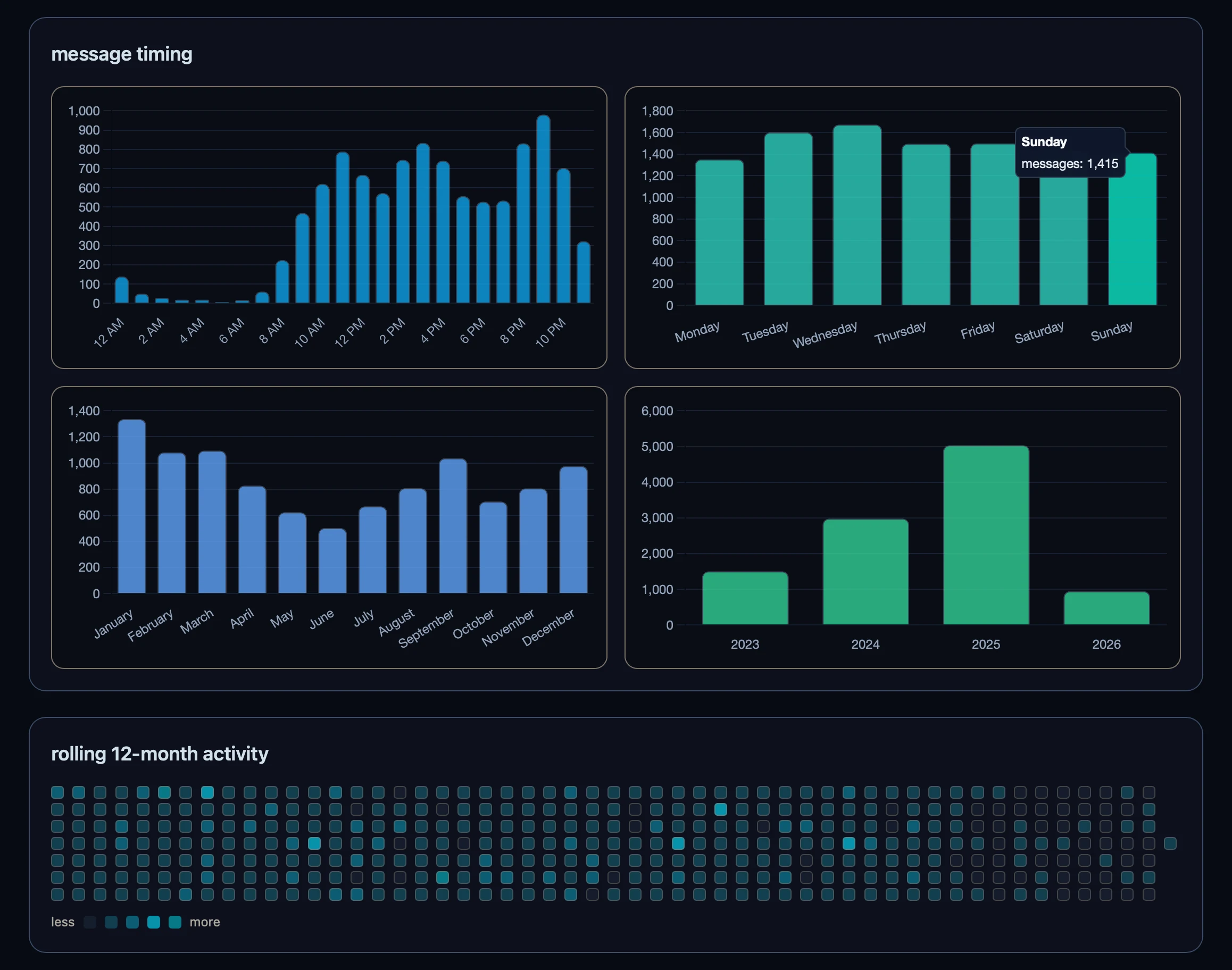
THE LIMITATIONS: This project is really a personal proof of concept. It works for me and for anyone willing to run docker compose up. It’s single user by design: the entire export is read into memory and a single worker handles everything. The goal was to prove to myself that I could take a complex real-world data structure, run analytics on it inside a proper backend, and wire the results to a frontend.
SCALING UP: A hosted version would be a different design entirely. I would store non-identifying aggregates in a database so users could log in and revisit their stats instead of re-uploading a large file every time. I would split the one big endpoint into an upload step plus separate queries for each chart, and stream the parse instead of holding the whole export in RAM. Guaranteeing privacy, however, is a harder problem and part of why version 1 stayed local.
Code #
GitHub Repo: chatgpt_wrapped